Gemini 3.0 vs Grok 4.1: care este mai buna inteligenta artificiala

Google Gemini 3.0 și Grok 4.1 de la Elon Musk ocupă în prezent primele poziții în clasamentul LMArena, o platformă publică care evaluează modelele AI majore pe baza voturilor utilizatorilor reali.

Am testat ambele sisteme de inteligență artificială prin nouă provocări distincte - de la puzzle-uri logice la sarcini de programare, scriere creativă și autoreflecție - pentru a vedea cum gestionează fiecare tipurile de cereri pe care utilizatorii le adresează în mod obișnuit asistenților AI.
Testele de raționament și logică
La prima provocare, care implica măsurarea exactă a 45 de minute folosind două corzi care se ard în 60 de minute fiecare, Grok 4.1 a oferit o explicație mai naturală, adresând mai bine problema ratelor inconsistente de ardere.

Pentru paradoxul berberului care își rade doar pe cei care nu se rad singuri, Gemini 3.0 a câștigat prin prezentarea mai echilibrată a contradicției logice, folosind un format clar if/then.
Programarea și debugging-ul
În testele de cod, Gemini 3.0 s-a remarcat prin răspunsuri mai educaționale cu explicații detaliate. Pentru o funcție Python de validare Sudoku, Google AI a oferit un cod mai curat și mai ușor de întreținut.

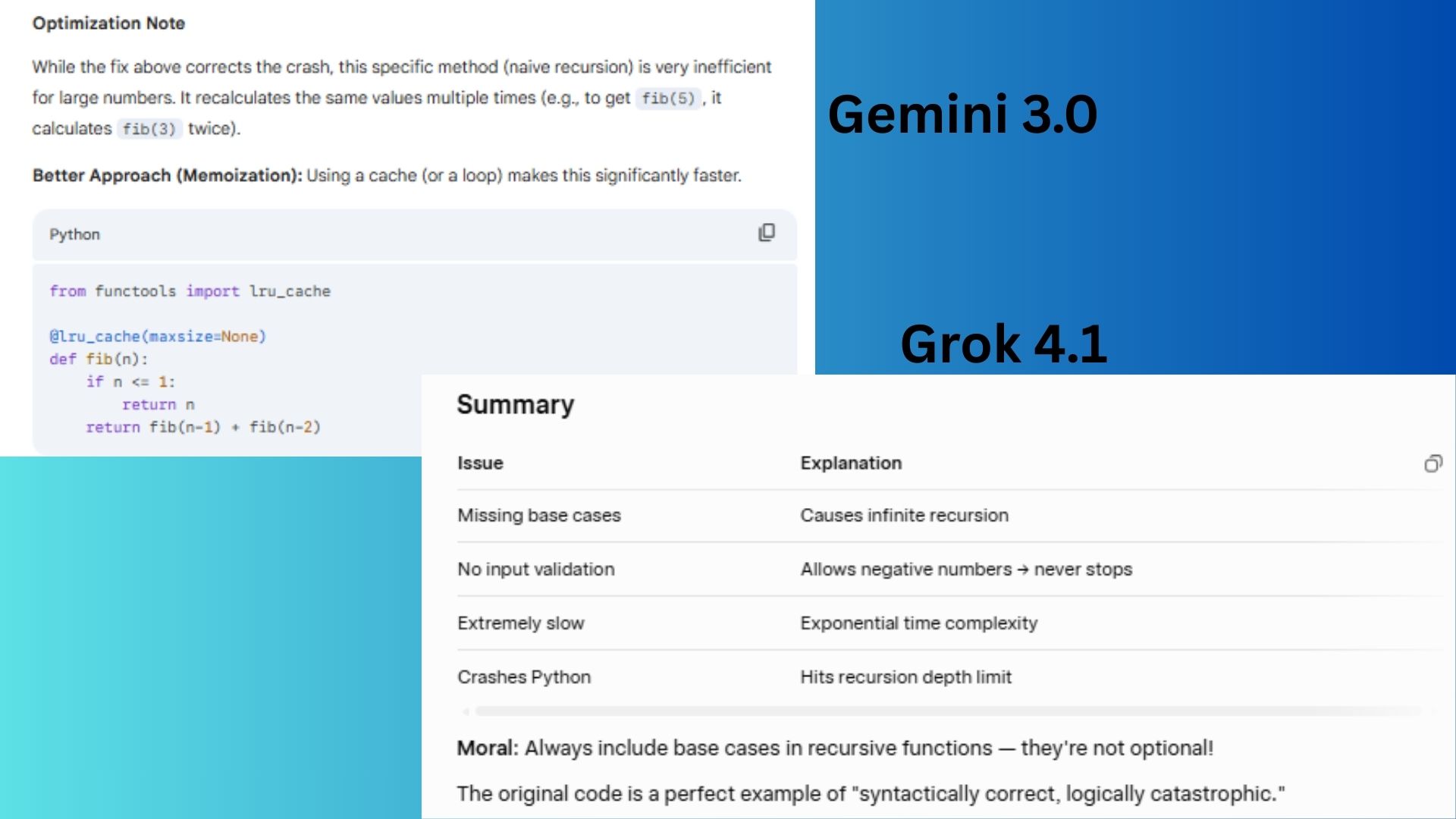
La debugging-ul unei funcții Fibonacci defecte, Gemini a identificat direct lipsa cazului de bază și a oferit o lecție practică de programare.
Creativitatea și înțelegerea nuanțată
Grok 4.1 a excelat la scrierea creativă, livrând o poveste de 200 de cuvinte cu o finalitate care recontextualizează complet narativea. Twist-ul de la erou la răufăcător a fost mai sofisticat și provocator.

Pentru argumentele pro și contra venitului de bază universal, Gemini a câștigat prin structură mai bună și o gamă mai largă de argumente, adresând direct problemele specifice ale sistemelor actuale de asistență socială.
Precizia factuală și autocunoașterea
Întrebat despre pictura Capelei Sixtine, Grok a furnizat informații mai complete și specifice, inclusiv context istoric și claritate structurală superioară.
Cel mai surprinzător rezultat a fost la testul de autocunoaștere. Gemini 3.0 a început să “halucineze”, repetând prompt-uri anterioare și încercând să le răspundă din nou, în timp ce Grok a răspuns clar și direct cu trei exemple specifice și realiste.
Testul decisiv
Pentru a sparge egalitatea, am cerut ambelor AI să scrie un mesaj de despărțire din perspectiva Lunii către Pământ - poetic, dar cu elemente științifice reale.

Gemini a înțeles mai profund sarcina, creând un text în format de mesaj real (“Hey. Avem nevoie să vorbim.”) și țesând conceptele științifice în narativea emoțională a unei despărțiri. Metaforele au fost mai ascuțite și rezultatul mai memorabil.
Câștigătorul general: Gemini
Pe parcursul celor nouă runde plus testul decisiv, Gemini 3.0 s-a detașat. Deși știam cât de aproape sunt pe clasamente, a fost surprinzător să văd că Grok a câștigat atât de multe runde.
Altă surpriză a fost halucinația lui Gemini - prima dată când am văzut acest fenomen în sutele de ore de testare a chatbot-urilor. Ultima întrebare a dezechilibrat complet Gemini, deși a performat excelent la suportul pentru debugging și explicațiile nuanțate.
Pe măsură ce aceste modele continuă să evolueze, comparațiile directe ajută să înțelegem nu doar care este “mai bun”, ci care este mai potrivit pentru tine și pentru ce sarcină specifică.
Sursa foto: www.tomsguide.com